Что такое хеш и хэширование простыми словами.

Сегодня у нас на очереди хеш. Что это такое? Зачем он нужен? Почему это слово так часто используется в интернете применительно к совершенно разным вещам? Имеет ли это какое-то отношение к хештегам или хешссылкам? Где применяют хэш, как вы сами можете его использовать? Что такое хэш-функция и хеш-сумма? Причем тут коллизии?
«>
Все это (или почти все) вы узнаете из этой маленькой заметки. Поехали…
Что такое хеш и хэширование простыми словами
Слово хеш происходит от английского «hash», одно из значений которого трактуется как путаница или мешанина. Собственно, это довольно полно описывает реальное значение этого термина. Часто еще про такой процесс говорят «хеширование», что опять же является производным от английского hashing (рубить, крошить, спутывать и т.п.).
Появился этот термин в середине прошлого века среди людей занимающихся обработках массивов данных. Хеш-функция позволяла привести любой массив данных к числу заданной длины. Например, если любое число (любой длинны) начать делить много раз подряд на одно и то же простое число, то полученный в результате остаток от деления можно будет называть хешем. Для разных исходных чисел остаток от деления (цифры после запятой) будет отличаться.
Для обычного человека это кажется белибердой, но как ни странно в наше время без хеширования практически невозможна работа в интернете. Так что же это такая за функция? На самом деле она может быть любой (приведенный выше пример это не есть реальная функция — он придуман мною чисто для вашего лучшего понимания принципа). Главное, чтобы результаты ее работы удовлетворяли приведенным ниже условиям.
Зачем нужен хэш
Смотрите, еще пример. Есть у вас текст в файле. Но на самом деле это ведь не текст, а массив цифровых символов (по сути число). Как вы знаете, в компьютерной логике используются двоичные числа (ноль и единица). Они запросто могут быть преобразованы в шестнадцатиричные цифры, над которыми можно проводить математические операции. Применив к ним хеш-функцию мы получим на выходе (после ряда итераций) число заданной длины (хеш-сумму).
Если мы потом в исходном текстовом файле поменяем хотя бы одну букву или добавим лишний пробел, то повторно рассчитанный для него хэш уже будет отличаться от изначального (вообще другое число будет). Доходит, зачем все это нужно? Ну, конечно же, для того, чтобы понять, что файл именно тот, что и должен быть. Это можно использовать в целом ряде аспектов работы в интернете и без этого вообще сложно представить себе работу сети.
Где и как используют хеширование
Например, простые хэш-функции (не надежные, но быстро рассчитываемые) применяются при проверке целостности передачи пакетов по протоколу TCP/IP (и ряду других протоколов и алгоритмов, для выявления аппаратных ошибок и сбоев — так называемое избыточное кодирование). Если рассчитанное значение хеша совпадает с отправленным вместе с пакетом (так называемой контрольной суммой), то значит потерь по пути не было (можно переходить к следующему пакету).
А это, ведь на минутку, основной протокол передачи данных в сети интернет. Без него никуда. Да, есть вероятность, что произойдет накладка — их называют коллизиями. Ведь для разных изначальных данных может получиться один и тот же хеш. Чем проще используется функция, тем выше такая вероятность. Но тут нужно просто выбирать между тем, что важнее в данный момент — надежность идентификации или скорость работы. В случае TCP/IP важна именно скорость. Но есть и другие области, где важнее именно надежность.
Похожая схема используется и в технологии блокчейн, где хеш выступает гарантией целостности цепочки транзакций (платежей) и защищает ее от несанкционированных изменений. Благодаря ему и распределенным вычислениям взломать блокчен очень сложно и на его основе благополучно существует множество криптовалют, включая самую популярную из них — это биткоин. Последний существует уже с 2009 год и до сих пор не был взломан.
Более сложные хеш-функции используются в криптографии. Главное условие для них — невозможность по конечному результату (хэшу) вычислить начальный (массив данных, который обработали данной хеш-функцией). Второе главное условие — стойкость к коллизиями, т.е. низкая вероятность получения двух одинаковых хеш-сумм из двух разных массивов данных при обработке их этой функцией. Расчеты по таким алгоритмам более сложные, но тут уже главное не скорость, а надежность.
Так же хеширование используется в технологии электронной цифровой подписи. С помощью хэша тут опять же удостоверяются, что подписывают именно тот документ, что требуется. Именно он (хеш) передается в токен, который и формирует электронную цифровую подпись. Но об этом, я надеюсь, еще будет отдельная статья, ибо тема интересная, но в двух абзацах ее не раскроешь.
Для доступа к сайтам и серверам по логину и паролю тоже часто используют хеширование. Согласитесь, что хранить пароли в открытом виде (для их сверки с вводимыми пользователями) довольно ненадежно (могут их похитить). Поэтому хранят хеши всех паролей. Пользователь вводит символы своего пароля, мгновенно рассчитывается его хеш-сумма и сверяется с тем, что есть в базе. Надежно и очень просто. Обычно для такого типа хеширования используют сложные функции с очень высокой криптостойкостью, чтобы по хэшу нельзя было бы восстановить пароль.
Какими свойствами должна обладать хеш-функция
Хочу систематизировать кое-что из уже сказанного и добавить новое.
- Как уже было сказано, функция эта должна уметь приводить любой объем данных (а все они цифровые, т.е. двоичные, как вы понимаете) к числу заданной длины (по сути это сжатие до битовой последовательности заданной длины хитрым способом).
- При этом малейшее изменение (хоть на один бит) входных данных должно приводить к полному изменению хеша.
- Она должна быть стойкой в обратной операции, т.е. вероятность восстановления исходных данных по хешу должна быть весьма низкой (хотя последнее сильно зависит от задействованных мощностей)
- В идеале она должна иметь как можно более низкую вероятность возникновения коллизий. Согласитесь, что не айс будет, если из разных массивов данных будут часто получаться одни и те же значения хэша.
- Хорошая хеш-функция не должна сильно нагружать железо при своем исполнении. От этого сильно зависит скорость работы системы на ней построенной. Как я уже говорил выше, всегда имеется компромисс между скорость работы и качеством получаемого результата.
- Алгоритм работы функции должен быть открытым, чтобы любой желающий мог бы оценить ее криптостойкость, т.е. вероятность восстановления начальных данных по выдаваемому хешу.
Хеш — это маркер целостности скачанных в сети файлов
Где еще можно встретить применение этой технологии? Наверняка при скачивании файлов из интернета вы сталкивались с тем, что там приводят некоторые числа (которые называют либо хешем, либо контрольными суммами) типа:
CRC32: 7438E546
MD5: DE3BAC46D80E77ADCE8E379F682332EB
SHA-1: 332B317FB97126B0F79F7AF5786EBC51E5CC82CF
Что это такое? И что вам с этим всем делать? Ну, как правило, на тех же сайтах можно найти пояснения по этому поводу, но я не буду вас утруждать и расскажу в двух словах. Это как раз и есть результаты работы различных хеш-функций (их названия приведены перед числами: CRC32, MD5 и SHA-1).
Зачем они вам нужны? Ну, если вам важно знать, что при скачивании все прошло нормально и ваша копия полностью соответствует оригиналу, то нужно будет поставить на свой компьютер программку, которая умеет вычислять хэш по этим алгоритмам (или хотя бы по некоторым их них).
После чего прогнать скачанные файлы через эту программку и сравнить полученные числа с приведенными на сайте. Если совпадают, то сбоев при скачивании не было, а если нет, то значит были сбои и есть смысл повторить закачку заново.
Популярные хэш-алгоритмы сжатия
- CRC32 — используется именно для создания контрольных сумм (так называемое избыточное кодирование). Данная функция не является криптографической. Есть много вариаций этого алгоритма (число после CRC означает длину получаемого хеша в битах), в зависимости от нужной длины получаемого хеша. Функция очень простая и нересурсоемкая. В связи с этим используется для проверки целостности пакетов в различных протоколах передачи данных.
- MD5 — старая, но до сих пор очень популярная версия уже криптографического алгоритма, которая создает хеш длиной в 128 бит. Хотя стойкость этой версии на сегодняшний день и не очень высока, она все равно часто используется как еще один вариант контрольной суммы, например, при скачивании файлов из сети.
- SHA-1 — криптографическая функция формирующая хеш-суммы длиной в 160 байт. Сейчас идет активная миграция в сторону SHA-2, которая обладает более высокой устойчивостью, но SHA-1 по-прежнему активно используется хотя бы в качестве контрольных сумм. Но она так же по-прежнему используется и для хранения хешей паролей в базе данных сайта (об этом читайте выше).
- ГОСТ Р 34.11-2012 — текущий российский криптографический (стойкий к взлому) алгоритм введенный в работу в 2013 году (ранее использовался ГОСТ Р 34.11-94). Длина выходного хеша может быть 256 или 512 бит. Обладает высокой криптостойкостью и довольно хорошей скоростью работы. Используется для электронных цифровых подписей в системе государственного и другого документооборота.
HashTab — вычисление хеша для любых файлов на компьютере
Раз уж зашла речь о программе для проверки целостности файлов (расчета контрольных сумм по разным алгоритмам хеширования), то тут, наверное, самым популярным решением будет HashTab.
Она бесплатна для личного некоммерческого использования и покрывает с лихвой все, что вам может понадобиться от подобного рода софта. После ее скачивания и установки запускать ничего не надо. Просто кликаете правой кнопкой мыши по нужному файлу в Проводнике (или ТоталКомандере) и выбираете самый нижний пункт выпадающего меню «Свойства»:

В открывшемся окне перейдите на вкладку «Хеш-суммы файлов», где будут отображены контрольные суммы, рассчитанные по нужным вам алгоритмам хэширования (задать их можно нажав на кнопку «Настройки» в этом же окне). По умолчанию отображаются три самых популярных:

Чтобы не сравнивать контрольные суммы визуально, можно числа по очереди вставить в рассположенное ниже поле (со знаком решетки) и нажать на кнопку «Сравнить файл».
Как видите, все очень просто и быстро. А главное эффективно.
Простой расчет контрольной суммы
При передачи данных по линиям связи, используется контрольная сумма, рассчитанная по некоторому алгоритму. Алгоритм часто сложный, конечно, он обоснован математически, но очень уж неудобен при дефиците ресурсов, например при программировании микроконтроллеров.

Чтобы упростить алгоритм, без потери качества, нужно немного «битовой магии», что интересная тема сама по себе.
Без контрольной суммы, передавать данные опасно, так как помехи присутствуют везде и всегда, весь вопрос только в их вероятности возникновения и вызываемых ими побочных эффектах. В зависимости от условий и выбирается алгоритм выявления ошибок и количество данных в контрольной сумме. Сложнее алгоритм, и больше контрольная сумма, меньше не распознанных ошибок.
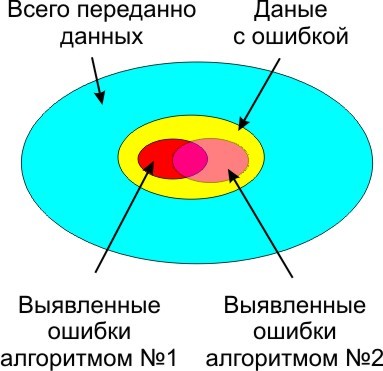
Причина помех на физическом уровне, при передаче данных.
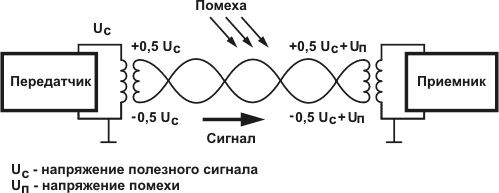
Вот пример самого типичного алгоритма для микроконтроллера, ставшего, фактически, промышленным стандартом с 1979 года.
Расчет контрольной суммы для протокола Modbus void crc_calculating(unsigned char puchMsg, unsigned short usDataLen) /*##Расчёт контрольной суммы##*/ { { unsigned char uchCRCHi = 0xFF ; /* Инициализация последнего байта CRC */ unsigned char uchCRCLo = 0xFF ; /* Инициализация первого байта CRC */ unsigned uIndex ; /* will index into CRC lookup table */ while (usDataLen—) /* pass through message buffer */ { uIndex = uchCRCHi ^ *puchMsg++ ; /* Расчёт CRC */ uchCRCLo = uchCRCLo ^ auchCRCHi ; uchCRCHi = auchCRCLo ; } return (uchCRCHi << 8 | uchCRCLo) ; /* Table of CRC values for high–order byte */ static unsigned char auchCRCHi = { 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40 }; /* Table of CRC values for low–order byte */ static char auchCRCLo = { 0x00, 0xC0, 0xC1, 0x01, 0xC3, 0x03, 0x02, 0xC2, 0xC6, 0x06, 0x07, 0xC7, 0x05, 0xC5, 0xC4, 0x04, 0xCC, 0x0C, 0x0D, 0xCD, 0x0F, 0xCF, 0xCE, 0x0E, 0x0A, 0xCA, 0xCB, 0x0B, 0xC9, 0x09, 0x08, 0xC8, 0xD8, 0x18, 0x19, 0xD9, 0x1B, 0xDB, 0xDA, 0x1A, 0x1E, 0xDE, 0xDF, 0x1F, 0xDD, 0x1D, 0x1C, 0xDC, 0x14, 0xD4, 0xD5, 0x15, 0xD7, 0x17, 0x16, 0xD6, 0xD2, 0x12, 0x13, 0xD3, 0x11, 0xD1, 0xD0, 0x10, 0xF0, 0x30, 0x31, 0xF1, 0x33, 0xF3, 0xF2, 0x32, 0x36, 0xF6, 0xF7, 0x37, 0xF5, 0x35, 0x34, 0xF4, 0x3C, 0xFC, 0xFD, 0x3D, 0xFF, 0x3F, 0x3E, 0xFE, 0xFA, 0x3A, 0x3B, 0xFB, 0x39, 0xF9, 0xF8, 0x38, 0x28, 0xE8, 0xE9, 0x29, 0xEB, 0x2B, 0x2A, 0xEA, 0xEE, 0x2E, 0x2F, 0xEF, 0x2D, 0xED, 0xEC, 0x2C, 0xE4, 0x24, 0x25, 0xE5, 0x27, 0xE7, 0xE6, 0x26, 0x22, 0xE2, 0xE3, 0x23, 0xE1, 0x21, 0x20, 0xE0, 0xA0, 0x60, 0x61, 0xA1, 0x63, 0xA3, 0xA2, 0x62, 0x66, 0xA6, 0xA7, 0x67, 0xA5, 0x65, 0x64, 0xA4, 0x6C, 0xAC, 0xAD, 0x6D, 0xAF, 0x6F, 0x6E, 0xAE, 0xAA, 0x6A, 0x6B, 0xAB, 0x69, 0xA9, 0xA8, 0x68, 0x78, 0xB8, 0xB9, 0x79, 0xBB, 0x7B, 0x7A, 0xBA, 0xBE, 0x7E, 0x7F, 0xBF, 0x7D, 0xBD, 0xBC, 0x7C, 0xB4, 0x74, 0x75, 0xB5, 0x77, 0xB7, 0xB6, 0x76, 0x72, 0xB2, 0xB3, 0x73, 0xB1, 0x71, 0x70, 0xB0, 0x50, 0x90, 0x91, 0x51, 0x93, 0x53, 0x52, 0x92, 0x96, 0x56, 0x57, 0x97, 0x55, 0x95, 0x94, 0x54, 0x9C, 0x5C, 0x5D, 0x9D, 0x5F, 0x9F, 0x9E, 0x5E, 0x5A, 0x9A, 0x9B, 0x5B, 0x99, 0x59, 0x58, 0x98, 0x88, 0x48, 0x49, 0x89, 0x4B, 0x8B, 0x8A, 0x4A, 0x4E, 0x8E, 0x8F, 0x4F, 0x8D, 0x4D, 0x4C, 0x8C, 0x44, 0x84, 0x85, 0x45, 0x87, 0x47, 0x46, 0x86, 0x82, 0x42, 0x43, 0x83, 0x41, 0x81, 0x80, 0x40 }; } }
Не слабый такой код, есть вариант без таблицы, но более медленный (необходима побитовая обработка данных), в любом случае способный вынести мозг как программисту, так и микроконтроллеру. Не во всякий микроконтроллер алгоритм с таблицей влезет вообще.
Давайте разберем алгоритмы, которые вообще могут подтвердить целостность данных невысокой ценой.
Бит четности (1-битная контрольная сумма)
На первом месте простой бит четности. При необходимости формируется аппаратно, принцип простейший, и подробно расписан в википедии. Недостаток только один, пропускает двойные ошибки (и вообще четное число ошибок), когда четность всех бит не меняется. Можно использовать для сбора статистики о наличии ошибок в потоке передаваемых данных, но целостность данных не гарантирует, хотя и снижает вероятность пропущенной ошибки на 50% (зависит, конечно, от типа помех на линии, в данном случае подразумевается что число четных и нечетных сбоев равновероятно).
Для включения бита четности, часто и код никакой не нужен, просто указываем что UART должен задействовать бит четности. Типично, просто указываем:
включение бита четности на микроконтроллере void setup(){ Serial.begin(9600,SERIAL_8N1); // по умолчанию, бит четности выключен; Serial1.begin(38400,SERIAL_8E1); // бит четности включен Serial.println(«Hello Computer»); Serial1.println(«Hello Serial 1»); }
Часто разработчики забывают даже, что UART имеет на борту возможность проверки бита четности. Кроме целостности передаваемых данных, это позволяет избежать устойчивого срыва синхронизации (например при передаче данных по радиоканалу), когда полезные данные могу случайно имитировать старт и стоп биты, а вместо данных на выходе буфера старт и стоп биты в случайном порядке.
8-битная контрольная сумма
Если контроля четности мало (а этого обычно мало), добавляется дополнительная контрольная сумма. Рассчитать контрольную сумму, можно как сумму ранее переданных байт, просто и логично
%20%2B%20byte(2)%20%2B%20byte(3)%2B%20...%20%2B%20byte(N))
Естественно биты переполнения не учитываем, результат укладываем в выделенные под контрольную сумму 8 бит. Можно пропустить ошибку, если при случайном сбое один байт увеличится на некоторое значение, а другой байт уменьшится на то же значение. Контрольная сумма не изменится. Проведем эксперимент по передаче данных. Исходные данные такие:
- Блок данных 8 байт.
- Заполненность псевдослучайными данными Random($FF+1)
- Случайным образом меняем 1 бит в блоке данных операцией XOR со специально подготовленным байтом, у которого один единичный бит на случайной позиции.
- Повторяем предыдущий пункт 10 раз, при этом может получится от 0 до 10 сбойных бит (2 ошибки могут накладываться друг на друга восстанавливая данные), вариант с 0 сбойных бит игнорируем в дальнейшем как бесполезный для нас.
Передаем виртуальную телеграмму N раз. Идеальная контрольная сумма выявит ошибку по количеству доступной ей информации о сообщении, больше информации, выше вероятность выявления сбойной телеграммы. Вероятность пропустить ошибку, для 1 бита контрольной суммы:
%3D0.5) .
.
Для 8 бит:
%3D1%3A256) ,
,
на 256 отправленных телеграмм с ошибкой, одна пройдет проверку контрольной суммы. Смотрим статистику от виртуальной передачи данных, с помощью простой тестовой программы:
Статистика1: 144 (тут и далее — вероятность прохождения ошибки)
1: 143
1: 144
1: 145
1: 144
1: 142
1: 143
1: 143
1: 142
1: 140
Общее число ошибок 69892 из 10 млн. итераций, или 1: 143.078
Или условный КПД=55%, от возможностей «идеальной» контрольной суммы. Такова плата за простоту алгоритма и скорость обработки данных. В целом, для многих применений, алгоритм работоспособен. Используется одна операция сложения и одна переменная 8-битовая. Нет возможности не корректной реализации. Поэтому алгоритм и применяется в контроллерах ADAMS, ICP, в составе протокола DCON (там дополнительно может быть включен бит четности, символы только ASCI, что так же способствует повышению надежности передачи данных и итоговая надежность несколько выше, так как часть ошибок выявляется по другим, дополнительным признакам, не связанных с контрольной суммой).
Не смотря на вероятность прохождения ошибки 1:143, вероятность обнаружения ошибки лучше, чем 1:256 невозможна теоретически. Потери в качестве работы есть, но не всегда это существенно. Если нужна надежность выше, нужно использовать контрольную сумму с большим числом бит. Или, иначе говоря, простая контрольная сумма, недостаточно эффективно использует примерно 0.75 бита из 8 имеющихся бит информации в контрольной сумме.
Для сравнения применим, вместо суммы, побитовое сложение XOR. Стало существенно хуже, вероятность обнаружения ошибки 1:67 или 26% от теоретического предела. Упрощенно, это можно объяснить тем, что XOR меняет при возникновении ошибке еще меньше бит в контрольной сумме, ниже отклик на единичный битовый сбой, и повторной ошибке более вероятно вернуть контрольную сумму в исходное состояние.
Так же можно утверждать, что контрольная сумма по XOR представляет из себя 8 независимых контрольных сумм из 1 бита. Вероятность того, что ошибка придется на один из 8 бит равна 1:8, вероятность двойного сбоя 1:64, что мы и наблюдаем, теоретическая величина совпала с экспериментальными данными.
Нам же нужен такой алгоритм, чтобы заменял при единичной ошибке максимальное количество бит в контрольной сумме. Но мы, в общей сложности, ограниченны сложностью алгоритма, и ресурсами в нашем распоряжении. Не во всех микроконтроллерах есть аппаратный блок расчета CRC. Но, практически везде, есть блок умножения. Рассчитаем контрольную сумму как произведение последовательности байт, на некоторую «магическую» константу:
CRC=CRC + byte*211
Константа должна быть простой, и быть достаточно большой, для изменения большего числа бит после каждой операции, 211 вполне подходит, проверяем:
Статистика1: 185
1: 186
1: 185
1: 185
1: 193
1: 188
1: 187
1: 194
1: 190
1: 200
Всего 72% от теоретического предела, небольшое улучшение перед простой суммой. Алгоритм в таком виде не имеет смысла. В данном случае теряется важная информация из отбрасываемых старших 8..16 бит, а их необходимо учитывать. Проще всего, смешать функцией XOR с младшими битами 1..8. Приходим к еще более интенсивной модификации контрольной суммы, желательно с минимальным затратами ресурсов. Добавляем фокус из криптографических алгоритмов
CRC=CRC + byte*211 CRC= CRC XOR (CRC SHR 8); // «миксер» битовый, далее его применяем везде CRC=CRC AND $FF; //или просто возвращаем результат как 8, а не 16 бит
- Промежуточная CRC для первого действия 16-битная (после вычислений обрезается до 8 бит) и в дальнейшем работаем как с 8-битной, если у нас 8-битный микроконтроллер это ускорит обработку данных.
- Возвращаем старшие биты и перемешиваем с младшими.
Проверяем:
Статистика1: 237
1: 234
1: 241
1: 234
1: 227
1: 238
1: 235
1: 233
1: 231
1: 236
Результат 91% от теоретического предела. Вполне годится для применения.
Если в микроконтроллере нет блока умножения, можно имитировать умножение операций сложения, смещения и XOR. Суть процесса такая же, модифицированный ошибкой бит, равномерно «распределяется» по остальным битам контрольной суммы.
CRC := (CRC shl 3) + byte; CRC := (CRC shl 3) + byte; CRC:=(CRC XOR (CRC SHR 8)) ; // как и в предыдущем алгоритме
Результат:
Статистика1: 255
1: 257
1: 255
1: 255
1: 254
1: 255
1: 250
1: 254
1: 256
1: 254
На удивление хороший результат. Среднее значение 254,5 или 99% от теоретического предела, операций немного больше, но все они простые и не используется умножение.
Если для внутреннего хранения промежуточных значений контрольной суммы отдать 16 бит переменную (но передавать по линии связи будем только младшие 8 бит), что не проблема даже для самого слабого микроконтроллера, получим некоторое улучшение работы алгоритма. В целом экономить 8 бит нет особого смысла, и 8-битовая промежуточная переменная использовалась ранее просто для упрощения понимания работы алгоритма.
Статистика1: 260
1: 250
1: 252
1: 258
1: 261
1: 255
1: 254
1: 261
1: 264
1: 262
Что соответствует 100.6% от теоретического предела, вполне хороший результат для такого простого алгоритма из одной строчки:
CRC:=CRC + byte*44111; // все переменные 16-битные
Используется полноценное 16-битное умножение. Опять же не обошлось без магического числа 44111 (выбрано из общих соображений без перебора всего подмножества чисел). Более точно, константу имеет смысл подбирать, только определившись с предполагаемым типом ошибок в линии передачи данных.
Столь высокий результат объясняется тем, что 2 цикла умножения подряд, полностью перемешивают биты, что нам и требовалось. Исключением, похоже, является последний байт телеграммы, особенно его старшие биты, они не полностью замешиваются в контрольную сумму, но и вероятность того, что ошибка придется на них невелика, примерно 4%. Эта особенность практически ни как не проявляется статистически, по крайней мере на моем наборе тестовых данных и ошибке ограниченной 10 сбойными битами. Для исключения этой особенности можно делать N+1 итераций, добавив виртуальный байт в дополнение к имеющимся в тестовом блоке данных (но это усложнение алгоритма).
Вариант без умножения с аналогичным результатом. Переменная CRC 16-битная, данные 8-битные, результат работы алгоритма — младшие 8 бит найденной контрольной суммы:
CRC := (CRC shl 2) + CRC + byte; CRC := (CRC shl 2) + CRC + byte; CRC:=(CRC XOR (CRC SHR 8));
Результат 100.6% от теоретического предела.
Вариант без умножения более простой, оставлен самый минимум функций, всего 3 математических операции:
CRC:=byte + CRC; CRC:=CRC xor (CRC shr 2);
Результат 86% от теоретического предела.
В этом случае потери старших бит нет, они возвращаются в младшую часть переменной через функцию XOR (битовый миксер).
Небольшое улучшение в некоторых случаях дает так же:
- Двойной проход по обрабатываемым данным. Но ценой усложнения алгоритма (внешний цикл нужно указать), ценой удвоения времени обработки данных.
- Обработка дополнительного, виртуального байта в конце обрабатываемых данных, усложнения алгоритма и времени работы алгоритма практически нет.
- Использование переменной для хранения контрольной суммы большей по разрядности, чем итоговая контрольная сумма и перемешивание младших бит со старшими.
Результат работы рассмотренных алгоритмов, от простых и слабых, к сложным и качественным:
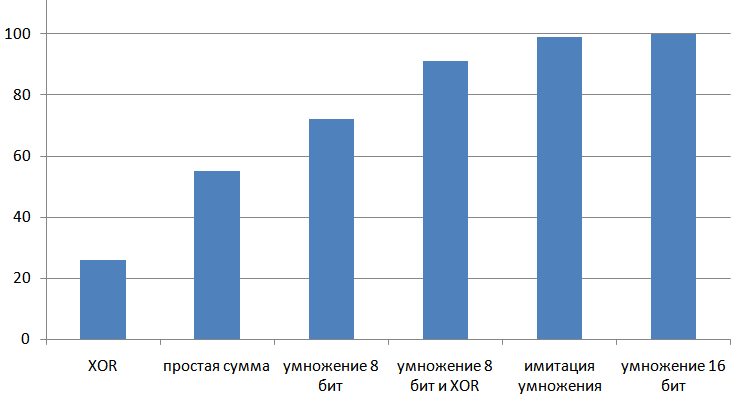
16-битная контрольная сумма
Далее, предположим что нам мало 8 бит для формирования контрольной суммы.

Следующий вариант 16 бит, и теоретическая вероятность ошибки переданных данных 1:65536, что намного лучше. Надежность растет по экспоненте. Но, как побочный эффект, растет количество вспомогательных данных, на примере нашей телеграммы, к 8 байтам полезной информации добавляется 2 байта контрольной суммы.
Простые алгоритмы суммы и XOR, применительно к 16-битной и последующим CRC не рассматриваем вообще, они практически не улучают качество работы, по сравнению с 8-битным вариантов.
Модифицируем алгоритм для обработки контрольной суммы разрядностью 16 бит, надо отметить, что тут так же есть магическое число 8 и 44111, значительное и необоснованное их изменение ухудшает работу алгоритма в разы.
CRC:=CRC + byte16*44111; //все данные 16-битные CRC:=CRC XOR (CRC SHR 8);
Результат:
Статистика1: 43478
1: 76923
1: 83333
1: 50000
1: 83333
1: 100000
1: 90909
1: 47619
1: 50000
1: 90909
Что соответствует 109% от теоретического предела. Присутствует ошибка измерений, но это простительно для 10 млн. итераций. Так же сказывается алгоритм создания, и вообще тип ошибок. Для более точного анализа, в любом случае нужно подстраивать условия под ошибки в конкретной линии передачи данных.
Дополнительно отмечу, что можно использовать 32-битные промежуточные переменные для накопления результата, а итоговую контрольную сумму использовать как младшие 16 бит. Во многих случаях, при любой разрядности контрольной суммы, так несколько улучшается качество работы алгоритма.
32-битная контрольная сумма
Перейдем к варианту 32-битной контрольной суммы. Появляется проблема со временем отводимым для анализа статистических данных, так как число переданных телеграмм уже сравнимо с 2^32. Алгоритм такой же, магические числа меняются в сторону увеличения
CRC:=CRC+byte32*$990C9AB5; CRC:=CRC XOR (CRC SHR 16);
За 10 млн. итераций ошибка не обнаружена. Чтобы ускорить сбор статистики обрезал CRC до 24 бит:
CRC = CRC AND $FFFFFF;
Результат, из 10 млн. итераций ошибка обнаружена 3 раза
Статистика1: 1000000
1: no
1: no
1: no
1: 1000000
1: no
1: 1000000
1: no
1: no
1: no
Вполне хороший результат и в целом близок к теоретическому пределу для 24 бит контрольной суммы (1:16777216). Тут надо отметить что функция контроля целостности данных равномерно распределена по всем битам CRC, и вполне возможно их отбрасывание с любой стороны, если есть ограничение на размер передаваемой CRC.
Для полноценных 32 бит, достаточно долго ждать результата, ошибок просто нет, за приемлемое время ожидания.
Вариант без умножения:
CRC := (CRC shl 5) + CRC + byte; CRC := (CRC shl 5) + CRC; CRC:=CRC xor (CRC shr 16);
Сбоя для полноценной контрольной суммы дождаться не получилось. Контрольная сумма урезанная до 24 бит показывает примерно такие же результаты, 8 ошибок на 100 млн. итераций. Промежуточная переменная CRC 64-битная.
64-битная контрольная сумма
Ну и напоследок 64-битная контрольная сумма, максимальная контрольная сумма, которая имеет смысл при передачи данных на нижнем уровне:
CRC:=CRC+byte64*$5FB7D03C81AE5243; CRC:=CRC XOR (CRC SHR 8); // магическое число 1..20
Дождаться ошибки передачи данных, до конца существования вселенной, наверное не получится 🙂

Метод аналогичный тому, какой применили для CRC32 показал аналогичные результаты. Больше бит оставляем, выше надежность в полном соответствии с теоретическим пределом. Проверял на младших 20 и 24 битах, этого кажется вполне достаточным, для оценки качества работы алгоритма.
Так же можно применить для 128-битных чисел (и еще больших), главное подобрать корректно 128-битные магические константы. Но это уже явно не для микроконтроллеров, такие числа и компилятор не поддерживает.
В целом метод умножения похож на генерацию псевдослучайной последовательности, только с учетом полезных данных участвующих в процессе.
Рекомендую к использованию в микроконтроллерах, или для проверки целостности любых переданных данных. Вполне рабочий метод, уже как есть, не смотря на простоту алгоритма.
Мой проект по исследованию CRC на гитхаб.
Далее интересно было бы оптимизировать алгоритм на более реальных данных (не псевдослучайные числа по стандартному алгоритму), подобрать более подходящие магические числа под ряд задач и начальных условий, думаю можно еще выиграть доли процента по качеству работы алгоритма. Оптимизировать алгоритм по скорости, читаемости кода (простоте алгоритма), качеству работы. В идеале получить и протестировать образцы кода для всех типов микроконтроллеров, для этого как-раз и нужны примеры с использованием умножения 8, 16, 32 битных данных, и без умножения вообще.
Проверка целостности файлов по контрольной сумме MD5
Часто случается что скаченный файл из интернета приходит поврежденным. Причиниы могут быть разные, ошибки серверов, отдающие файлы; антивирусы, вносящие изменения в файлы; ошибки скачивания в многопоточном режиме, ошибки на линии связи при передачи файлов. Конечный итога всегда один, либо файл не открывается или не запускается вообще, либо открывается, но не должным образом. Для определения чистоты файлы нам может помочь контрольная сумма MD5.
Алгоритм MD5, разработанный компанией RSA Data Security, Inc ( Message Digest Algorithm 5 — улучшеная версия MD4) это алгоритмом вычисления хеш-функции (message digest). Применяется данный алгоритм для различных целей — шифрование паролей, проверка целосности файлов, в приложениях криптографии и электронно-цифровых подписях для генерации ключа шифрования. При использовании алгоритма получаем хэш записи длиной 128 бит. Особенность алгоритма md5 заключается в том, что практически очень сложно, почти невозможно найти две строки, дающие одинаковый хеш (например два файла, у которых значение md5 будет одинаковым).
Расчет и проверка контрольных сумм MD5
Для расчета сумм MD5 можно найти много программ, например winMd5sum, md5summer, md5com, Total Commander умеет считать MD5 (Файл->Посчитать CRC сумму) и другие.
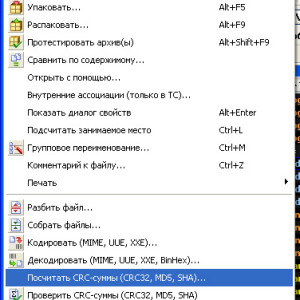
Проверка контрольных сумм в TotalCommander
Для пользователей Linux`ов существует команда md5sum.
Вобщем то все программы очень простые, и умеют создавать и проверять суммы MD5.
Пример очень маленькой программы
md5sum — очень маленькая программа, работает из командной строки. Загрузив md5sum.exe, необходимо скопировать её в отдельный каталог, в этот же каталог нужно поместить проверяемый файл. Программа работает из консоли.
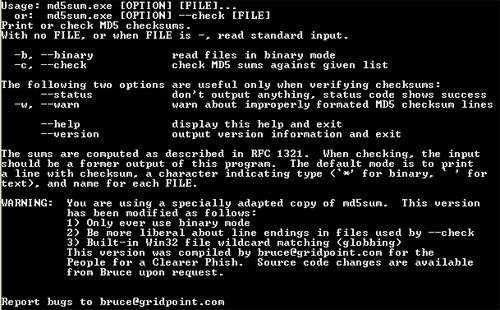
Пуск — Выполнить — cmd — указать путь до каталога, после чего можно проверять.
Для расчета суммы комманда: md5sum -b CYBERIA.rar >syb.md5
Программа создаст файл “syb.md5” c контрольной суммой файла CYBERIA.rar
Для проверки контрольных сумм: md5sum -с syb.md5
Применение
Закачивая архивы, а именно к ним мы будем давать MD5 т.к. любой файл будь то avi, mp3, exe, zip или другой файл мы архивируем, и в конце новости вставляем ссылку на файл .md5 или текстовой блок с суммами. После того как Вы скачали файлы и создали в этом каталоге файл md5 из текстового блока, проверяете этот файл с помощью одной из программ указанной выше.
С помощью MD5 можно не только проверять файлы, можно сравнивать файлы, проверять целосность баз данных, винчестеров и многое другое.
Что такое CRC SHA появилось в контекстном меню?
ЗловредностьПрочееПочему у чеснока кончики листьев фиолетовые?ZloyПрочееКто такая Эльвира Дорохова?si_surprisПрочееКакие интересные ники можно придумать для имени Полина, Поля?АстреяПрочееГде в ДНР можно получить права тракториста?Н-И-Н-Е-Л-ЬПрочееКаким образом информация представляется на ее носителе?PauleПрочееГде узнать код регистрации участника ОГЭ?Pavlik01ПрочееЧто являлось личной эмблемой Екатерины Медичи?TwisterСад и огородРасписание дачных автобусов Братск, где смотреть?HelenaПрочееСергей Михалков Праздник непослушания: чему учит сказка, главная мысль?ЧудесНеБываетПрочееЗаходер Птичья школа: краткое содержание, главная мысль, кто главные герои?ЛеоПрочееКак научиться видеть очень далеко, как видят орлы?MatildaПрочееКак убрать запах гари с одеяла/ пледа?SecretПрочееЧто означает ошибка Invalid card number?Юра_БеляевПрочееКак звали друга папы Карло?Monik-AРазвлеченияРыба с самой мелкой чёрной икрой — это какая и что о ней известно?LarsПрочееЖужа — это кто, как полное имя женщин, которых называют Жужа?ЯсноСолнышкоПрочееГде принимает травница матушка Лора?Киллер-76ПрочееЧто делать, если щавель цветет, пошел в стрелку?БабаЯга2017ПрочееГде в Новороссийске можно пожарить шашлыки?MrPresidentПрочееМожно ли пересаживать горох после прореживания?RaweOnceПрочееМожно ли забивать гвозди в пластик?
Скачивая файлы, программы или образы дисков вы наверняка замечали, что вместе с данными файлами часто распространяют и какие-то зашифрованные строки, которые называются контрольными или хеш суммами. В данной статье мы расскажем о том, что такое контрольная сумма, для чего ее используют и как проверить контрольную сумму для строк или файлов.
Что такое контрольная сумма
Контрольная сумма или хеш-сумма – это значение, которое было рассчитано по некоторому алгоритму на основе имеющихся файлов или данных. Особенностью контрольной суммы является то, что ее алгоритм, при одинаковых входных данных всегда выдает одинаковое значение. При этом малейшее изменение входных данных кардинально меняет значение контрольной суммы.
Эта особенность позволяет использовать контрольную сумму для проверки целостности файлов или данных. Например, вам нужно отправить какой-то файл, и вы хотите убедиться, что он не будет поврежден или изменен на своем пути к получателю. Для решения этой задачи можно использовать контрольную сумму. Высчитываете контрольную сумму и отправляете ее вместе с файлом. После чего получатель файла повторно высчитывает контрольную сумму файла и сравнивает ее с вашей контрольной суммой. Если значения совпадают, значит файл оригинальный, если нет, значит он получил какие-то изменения.
Также нужно упомянуть, что контрольную сумму нельзя использовать для получения исходных данных. То есть нельзя «расшифровать» хеш-сумму и получить данные которые были хешированы, хеш-сумму можно только сравнить с другой хеш-суммой. Это особенность открывает дополнительные возможности. Например, хеш-суммы используются для хранения паролей. Когда вы регистрируетесь на каком-то сайте и вводите свой пароль, то он не хранится на сервере в открытом виде. Вместо этого хранится только его контрольная сумма. А когда вы входите в свой аккаунт с использованием пароля, система получается ваш пароль, высчитывает его хеш-сумму и сравнивает с хеш-суммой, которая хранится на сервере. Если хеш-суммы совпали, значит пароль верный и вы можете войти в аккаунт, если хеш-суммы не совпадают, значит пароль не верный и вас перенаправляют на страницу для восстановления пароля.
Для высчитывания контрольной суммы существует множество различных алгоритмов или так называемых хеш-функций. Самыми известными и популярными алгоритмы являются: CRC32, MD5, SHA-1 и SHA-2. Но, есть и множество других алгоритмов, некоторые из которых имеют широкое применения, а некоторые используются только для специфических задач. При этом часть существующих алгоритмов признаны устаревшими или уязвимыми и больше не используются. Так, алгоритм MD5 практически полностью перестал использоваться поскольку выяснилось, что он может выдавать одинаковые значения для разных входных значений.
Для примера продемонстрируем, как выглядит контрольная сумма на практике. Например, возьмем строку «Hello, world!» и высчитаем ее контрольную сумму с использованием нескольких популярных алгоритмов.
Как видно, каждый алгоритм выдает значение, которое не имеет совершенно ничего общего с исходными данными. И сколько раз мы бы не высчитывали контрольную сумму строки «Hello, world!», мы каждый раз будем получать одни и те же значения.
Проверка контрольной суммы файла
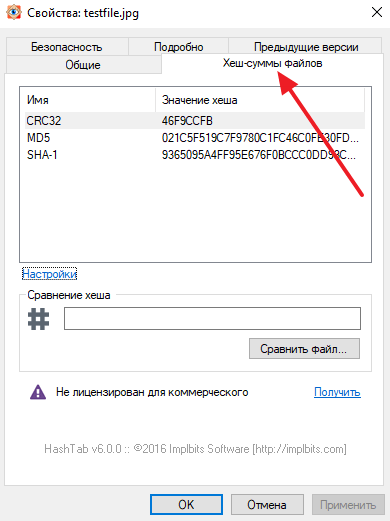
Если вам нужно проверить контрольную сумму файла (например, образа диска или программы), то вам понадобится специальная программа, которая умеет высчитывать контрольные суммы. Самой популярной программой такого рода является HashTab.
После установки данной программы в свойствах файла появится новая вкладка «Хеш-суммы файлов», в которой будет отображаться хеш-сумма выбранного вами файла.
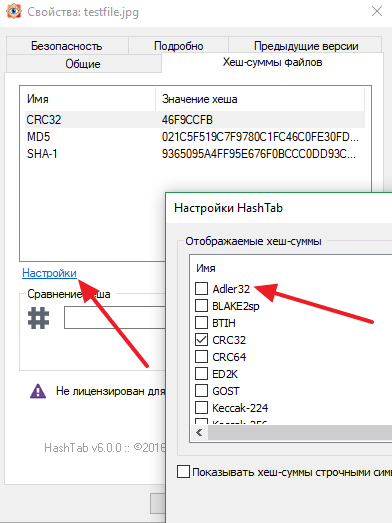
При этом пользователь можно изменить набор алгоритмов, которые программа HashTab использует для расчета хеш-суммы. Для этого нужно нажать на ссылку «Настройки», выбрать нужные алгоритмы и сохранить изменения с помощью кнопки «ОК».
Полученные значения контрольных сумм можно скопировать, для этого нужно кликнуть на значению с помощью правой кнопки мышки.
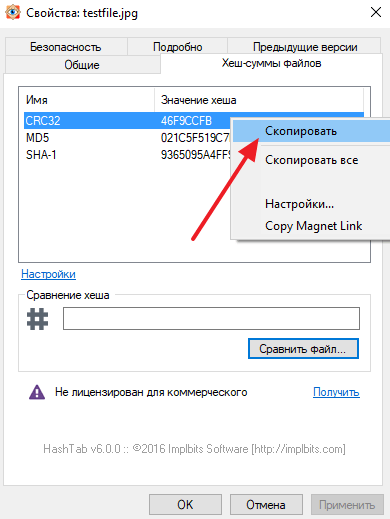
Также HashTab позволяет сравнивать файлы. Для этого нужно нажать на кнопку «Сравнить файл» и выбрать другой файл.
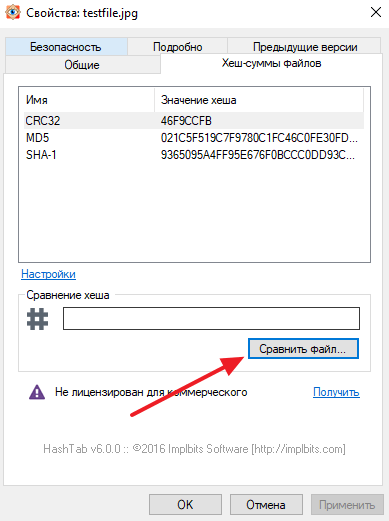
Программа HashTab является бесплатной для личного пользования, некоммерческих организаций и студентов. Скачать программу можно на официальном сайте https://implbits.com/products/hashtab/.
