Google
В Google можно распознавать неограниченное количество картинок, лишь бы они поместились на Google Drive. Нужно просто открыть картинку с Google диска с помощью Google Документов, и она автоматически распознается.
| Входные форматы | PDF , JPEG, PNG, GIF |
| Выходные форматы | Word, Open Document, RTF, Adobe PDF, HTML, Text Plain, Epub (но форматирование исчезает – нарушается компоновка картинок с текстом) |
| Размер файла | До 2 Мб |
| Ограничения | Ограничено только размером хранилищ Google. Качество исходника рекоменовано не меньше 10 пикселей по высоте для строки. |
| Качество | Так себе – качество распознавания свидетельства инн хуже, чем с Finereader. И ФИО, и номер инн полностью потеряны. |
Как пользоваться
У вас должен быть Google-аккаунт для пользования сервисом, если есть почта gmail – подойдет аккаунт от нее.
- Загрузите файл на страницу drive.google.com или выберите там уже загруженную картинку
- Нажмите правой кнопкой мыши на нужный файл.
- Выберите “Открыть с помощью” –> “Google Документы”.
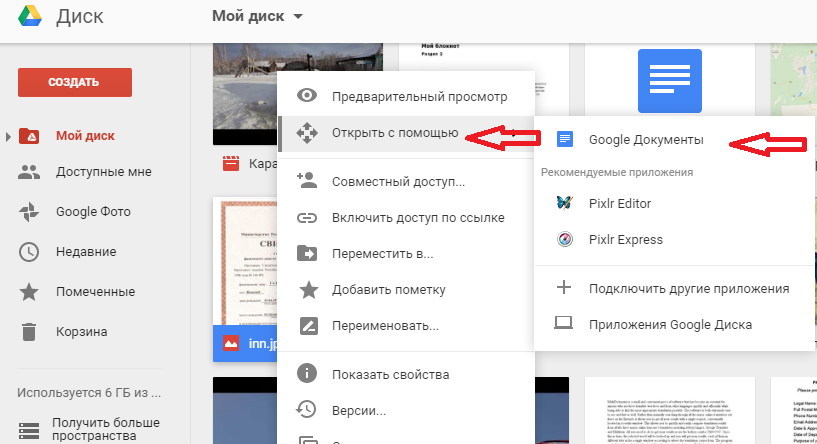
- Картинка преобразуется в документ Google и откроется на вкладке https://docs.google.com
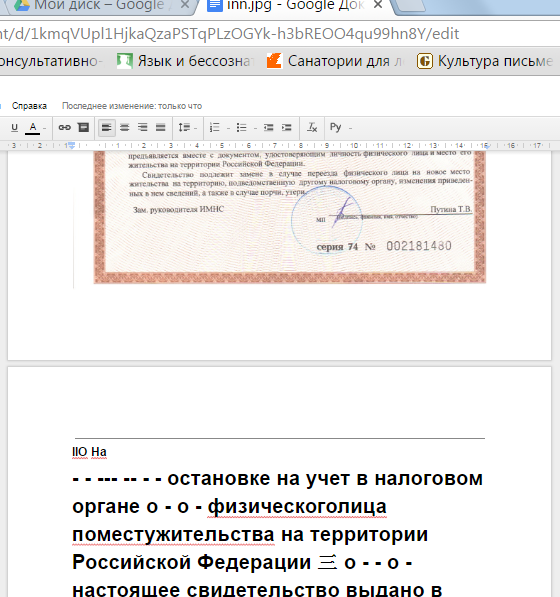
Распознавание текста онлайн без регистрации
Online OCR
Online OCR https://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:

Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
- Загрузите файл (щелкните «Select File»)
- Выберите язык и выходной формат
- Введите и щелкните «Convert»
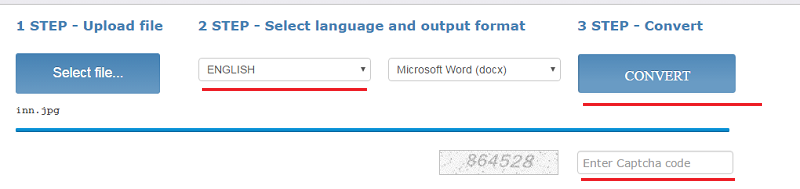
Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Можно распознавать как все целиком, так и выделить часть изображения для распознавания.
Как пользоваться
- Выберите файл или вставьте url файла и щелкните «Preview» – картинка загрузится и появится в окне браузера
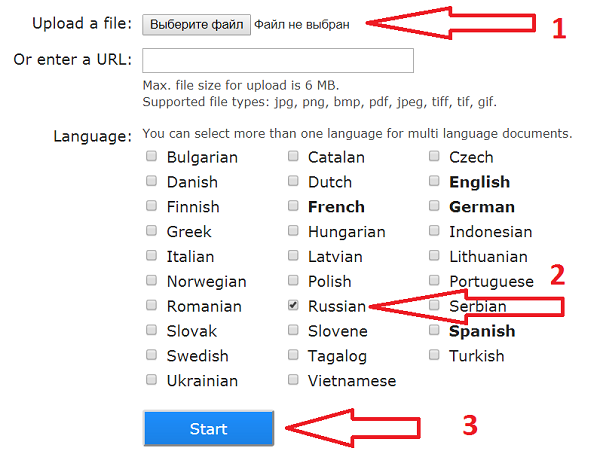 Не забудьте правильно указать язык.
Не забудьте правильно указать язык. - Выберите область сканирования (можно оставить целиком как есть)

- Выберите языки, на которых написан текст на картинке и щелкните кнопку «OCR»
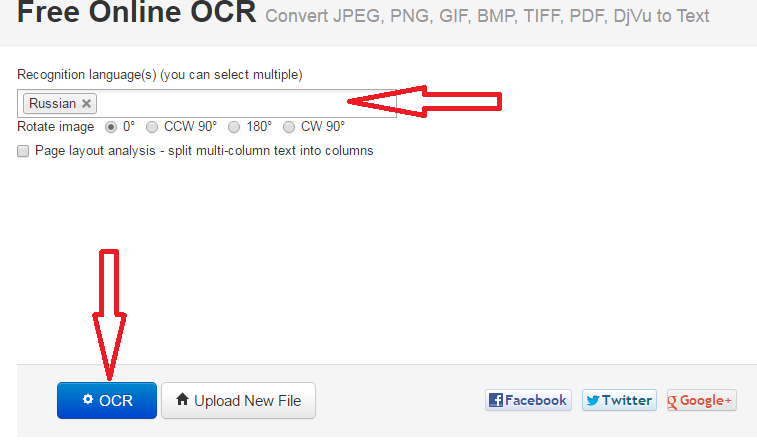
- Внизу появится окно с текстом
OCR Convert
OCR Convert https://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
- Загрузите файл, выберите язык и щелкните кнопку «Process»
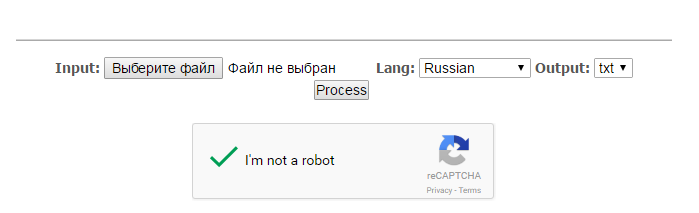
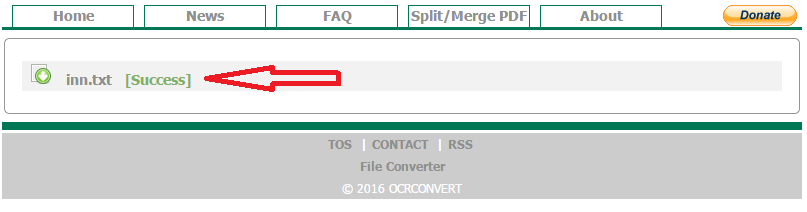
- Появится ссылка на файл с распознанным текстом
Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
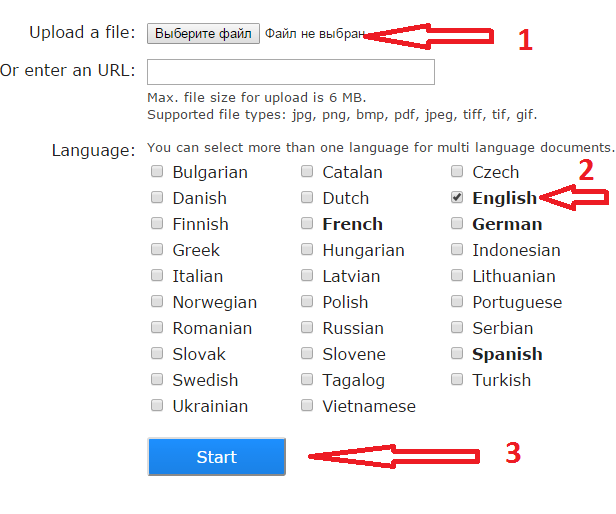
- Выберите файл
- Выберите языки на картинке
- Щелкните кнопку “Start”
I2OCR
I2OCR https://www.i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert. Замечено, что сервис временами не работает. |
- Выберите язык
- Загрузите файл
- Введите
- Щелкните кнопку «Extract text»
- По кнопке «Download» можно загрузить выходной файл в нужном формате
Яндекс OCR
Недавно обнаружила этот сервис, и он мне очень понравился качеством и простотой использования. Вообще то он предназначен для перевода загруженной картинки, но его можно использоваться и для распознавания текста с картинки. Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Просто перейдите на https://translate.yandex.ru/ocr, загрузите картинку (можно перетащить) и щелкните “Открыть в Переводчике”. Откроется как текст с картинки, так и перевод в правом поле.
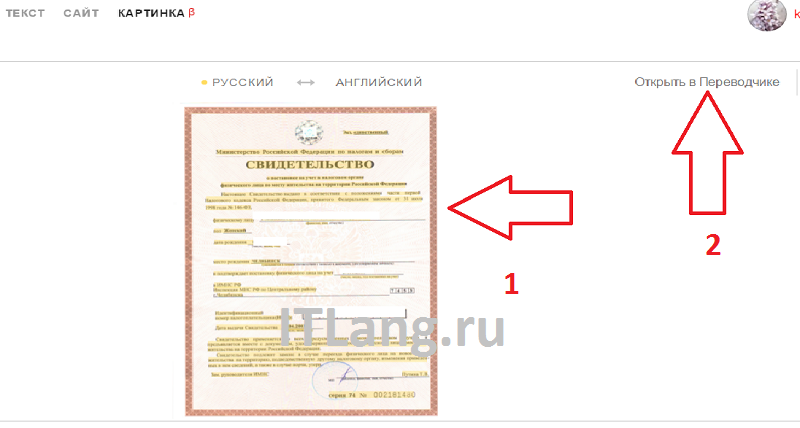
Перетащите картинку
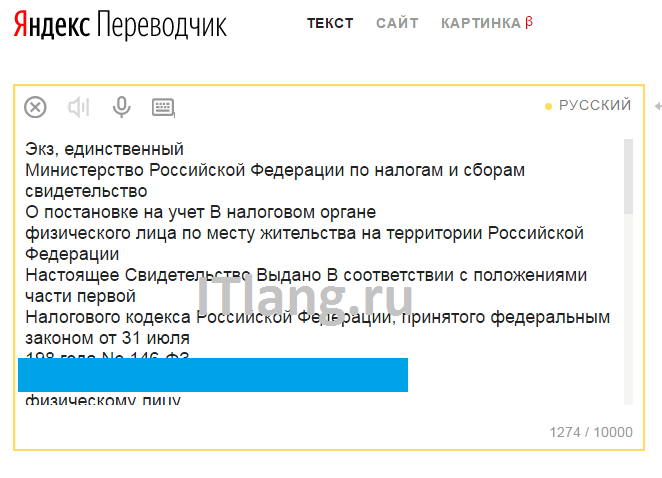
Результат распознавания
Convertio
Convertio hhttps://convertio.co/ru/ocr/ работает своеобразно, поэтому сравнивать его тяжело. В целом не понравился. Свидетельство ИНН, загруженное целиком, он не распознал совсем, так как плохо выделяет текст среди картинок. Не распозналось ни одного слова! Для его проверки я вырезала текстовый кусочек из ИНН и распознала его – это удалось сделать.
К тому же временами он зависает в попытках что-либо распознать.
| Входные форматы | pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp, webp |
| Выходные форматы | Text Plain, PDF, Word , Excel, Pptx, Djvu, Epub, Fb2, Csv |
| Размер файла | ?, зависит от тарифа |
| Ограничения | 10 страниц бесплатно, дальше тарифы от 7 долларов. |
| Качество | Сложно оценить – файл с картинками (ИНН) не распознал совсем, отдельно вырезанный кусок текста распознал. Замечено, что при распознавании сервис временами зависает, возможно ваши картинки ставятся в большую очередь на бесплатном тарифе. |
- Загрузите файл
- Выберите язык
- Выберите выходной формат
- Введите
- Щелкните “Преобразовать”
- Чтобы увидеть результат, промотайте наверх к форме загрузки файлов. Там же можно будет и скачать результат.
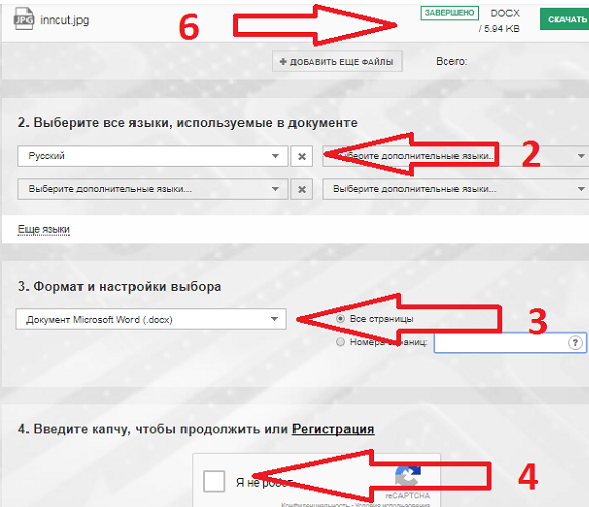
Интерфейс Convertio
Вырезанный и распознанный кусок (целиком не распознается):

Результат работы Convertio
Лучше всего документ распознал Abbyy Finereader и Online OCR. Кроме того, эти сервисы сохраняют форматирование файла: где нет текста, оставляют картинки и компонуют их с распознанным текстом. Из новых сервисов хорош Яндекс OCR.
Хуже всего сработал Free OCR – он распознал всего три слова.
Распознаем текст онлайн с картинок, отсканированных документов бесплатно и без регистрации
Приветствую вас, дорогие читатели блога. Сегодня я хочу рассказать вам о некоторых сервисах, которые давно у меня лежат в закладках. Речь пойдет о сервисах распознавания текста онлайн.

Наверное, у каждого был случай, когда вы хотели переписать какой-то текст с картинки или PDF файла. Это могли быть какие-то документы или просто красивая цитата. У меня таких случаев было немало и меня всегда выручали сервисы распознавания текста. Конечно, существуют и программы для этой цели, но я предпочитаю такие простые задачи делать онлайн.
Ниже вы можете увидеть перечень сервисов, благодаря которым распознать текст с изображения проще простого. Все сервисы абсолютно бесплатны и не требуют регистрации.
Принцип сервисов весьма прост. Вы загружаете изображение, содержащее текст, сервис его обрабатывает и выдает вам готовый текст, избавляя вас от его переписывания. Качество распознавания текста с изображения напрямую зависит от качества самого изображения.
Где можно распознать текст с PDF файла, картинки или фотографии бесплатно
Итак, вот список сервисов:
– позволяет распознать текст бесплатно с изображений таких форматов как: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сервис поддерживает множество языков. После распознания текста с картинки, его можно скопировать и вставить в свой документ.
— аналогичный предыдущему сервис, с тем лишь отличием, что здесь распознанный текст можно скачать в форматах Microsoft Word (docx), Microsoft Exel (xlsx), Text Plain (txt).
– сервис, поддерживающий форматы jpg, png, bmp, pdf, jpeg, tiff, tif и gif. Языков распознавания чуть меньше чем в предыдущих сервисах, но тоже немало. Скачать распознанный тест можно в txt формате.
– сервис, поддерживающий более 60 языков. Кроме основной функции распознавания текста с изображений, здесь есть такие инструменты как:
- Конвертация web-страницы в PDF;
- Преобразование web-страницы в изображение (скриншот);
- Генератор кнопок CSS3;
- Международные клавиатуры;
- Преобразователь формата изображений;
Качество извлечения текста с изображений
Особой разницы в качестве распознавания текста на изображениях между сервисами я не заметил, поэтому в качестве примера покажу лишь первый сервис.
Для примера я взял несколько изображений разного размера и качества изображенного текста.
Изображение 1 (790 X 588 px)
Изображение 2 (793 X 1024 px)
Изображение 3 (600 X 350 px)
И вот результат самого текста, который сервис распознал на картинке.
Результат 1 изображения:
Распознавание текста на изображении онлайн
Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы. Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии:
В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты.
Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть.
Обе OCR-программы для распознования текста отличаются друг от друга и могут давать разные результаты, что позволяет выбрать наиболее приемлемый вариант из двух.
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.
